
Anatomy of Apache Spark Application
Spark has become the go-to framework for big data processing, and for good reason: it's fast, versatile, and (once you get the hang of it) surprisingly elegant. But mastering it? That's a whole other story. Spark is packed with features and an architecture that feels simple on the surface but quickly grows in complexity. If you've ever struggled with long shuffles, weird partitioning issues, or mysterious memory errors, you know exactly what I mean.
This article is the third in a series on Apache Spark — created to help you get past the basics and into the real nuts and bolts of how it works, and how to make it work for you.
Where are we?
Let's pause and take stock of where we are in this series.
In the first post we talked about the playground Spark runs on — clusters, resource managers—all that infrastructure you need before a single line of code moves data.
In the second post we talked about how Spark thinks — it's core abstractions like RDDs, DataFrames, transformations, and actions. Basically, the theory.
Now we finally get to the fun part: what actually happens when your job runs: Spark job's life cycle. This is where all that abstract stuff suddenly becomes very real. Tasks start flying, executors spin up, and data shuffles across the cluster.
Spark Application Architecture Essentials
If you strip Spark down to its moving parts, it's basically a distributed to-do‑do list with a coordinator. Your code says, "I want to crunch this giant pile of data", and Spark figures out who does what, where, and when.
If you've ever stared at the Spark UI wondering why stage 2 has 400 tasks and stage 3 has 12, these are the components that are making that happen:
- Spark Driver — the brain of the operation. It turns your nice, innocent
mapandreduceByKeycalls into a DAG (Directed Acyclic Graph, if you don't recall) of tasks, sends them to the cluster, and keeps tabs on who's still alive. - Executors — the workers. They're JVM processes living on the cluster nodes, running tasks in parallel, caching RDDs, and shuffling data around. Spark scales because you can have hundreds of these chewing through partitions at the same time.
- Cluster Manager / Resource Manager — the landlord that owns the machines (the land of the cluster). Popular ones are YARN, Kubernetes, or Spark's standalone manager.
- Spark Context — the entry point to all of Spark's features. It's the Spark Driver's (see below) hotline to the cluster, letting it request executors, create RDDs, and manage shared variables. You only get one per JVM.
Each of these pieces is part of the pipeline that turns your "just run df.groupBy().count()" code into a swarm of distributed tasks.
Let's dive deeper into these components to understand their roles.
Spark Driver
The Driver is where a Spark application truly begins. Once the Driver spins up and takes charge, everything that happens in the cluster is dictated by this single process.
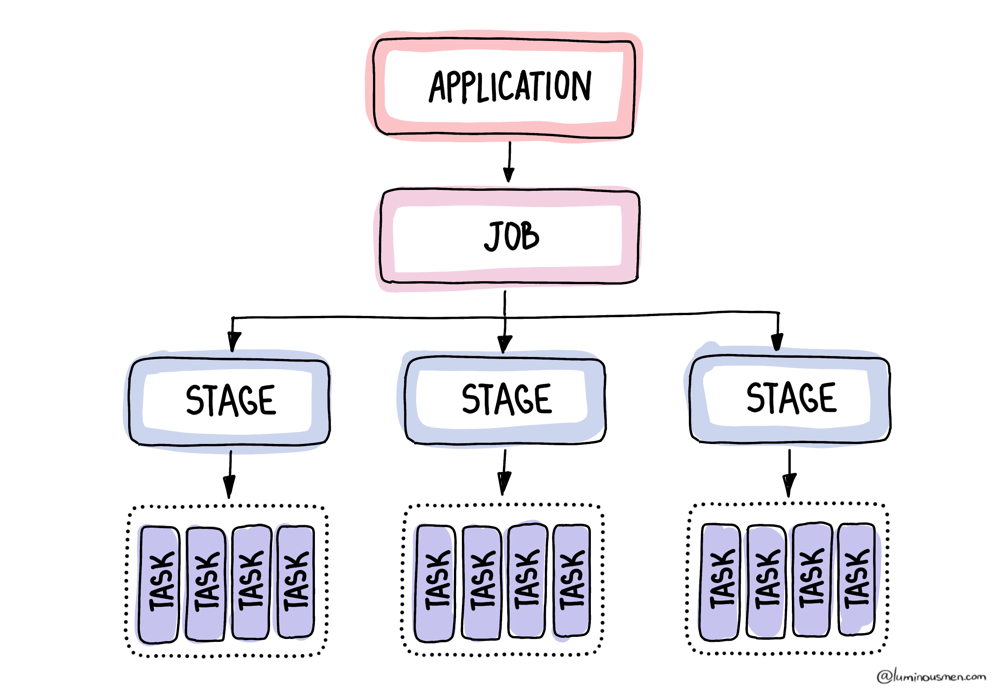
In the hierarchy of a Spark application (application → job → stage → task), the Driver is at the top — it manages the entire process from the top down in real time, orchestrating how work flows down from jobs to individual tasks on executors. Everything else in Spark exists to serve the plan that the Driver creates.
As your code runs and you define transformations, the Driver incrementally assembles them into a logical DAG of operations. Spark is lazy — these transformations only describe how to compute the data, not execute it. No actual computation happens until you call an action like collect or count. At that point, the Driver turns the logical DAG into a physical execution plan and starts running tasks on executors.
Execution isn't a single step. The Driver cuts the DAG into stages wherever a wide dependency appears. Each stage is then broken into tasks, one per data partition. These tasks are the actual work units that will eventually land on executors somewhere in the cluster.
Once the tasks exist, the Driver takes on the role of a scheduler. It talks to the Cluster Resource Manager to request resources, hands batches of tasks to available executors, and keeps a close eye on their progress. If an executor dies, the Driver knows which tasks were running there and can resubmit them elsewhere. This constant awareness is what allows Spark to tolerate node failures without losing your entire job.
At the same time, the Driver is the historian of the application. It keeps lineage information for RDDs (Resiliant Distributed Dataset) and partitions, maintains the logical-to-physical mapping of operations, and exposes this through the Spark UI.
Everything in your application — jobs, stages, and tasks — flows downward from the Driver. It is the single point from which high‑level logic becomes executable reality, quietly controlling the chaos of a distributed system.
In material terms, the Driver is just a JVM process. Where the Driver lives depends on how you launch the job. In client mode, it stays on your laptop or submission machine, orchestrating everything remotely. In cluster mode, it moves into the cluster itself, running on a dedicated node. In both cases, its existence is non‑negotiable — kill the Driver, and the application is gone. There's no Spark without the Driver.
How can the Driver can do so much? The Driver itself consists of several managers. Let's describe them one by one.
DAGScheduler
If the Driver is the brain, the DAGScheduler is the part that thinks in big pictures. It doesn't care about CPUs, threads, or executors. Instead, it stares at your logical plan — the DAG of RDD transformations — and figures out how to break it into stages.
One stage can run as long as its input partitions are available locally. The DAGScheduler's job is to translate logical operations into stage boundaries. It looks at your RDD lineage, identifies wide dependencies like groupByKey or join, and decides where data shuffles must occur. Every shuffle creates a stage boundary because data has to move between nodes.
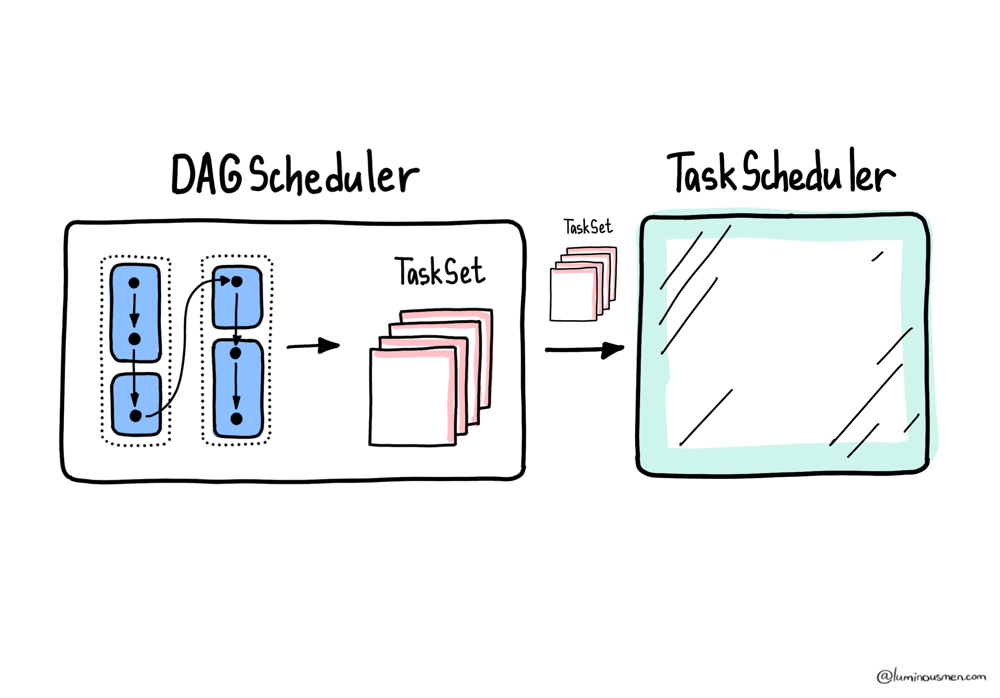
From there, the DAGScheduler breaks each stage into a set of tasks literally called TaskSets, one per partition, and sends them to the TaskScheduler. But it doesn't just generate tasks — it also tracks their lineage. This lineage allows Spark to recompute lost partitions in case of failure instead of starting your job from scratch.
DAGScheduler is also the one who decides job success or failure. If a stage can't make progress after repeated attempts — say, due to corrupted input data — it's the DAGScheduler that ultimately declares the job to have failed.
It is important to note that, the DAGScheduler makes dynamic decisions. It doesn't pre-schedule all stages at once. Instead, it reacts to stage completions and unlocks child stages on-the-fly.
TaskScheduler
Once the DAGScheduler has carved the DAG into stages and handed off a TaskSet for the next stage, the TaskScheduler. This is the part of Spark that stops thinking in lineage and starts thinking in terms of machines and slots.
The TaskScheduler doesn't care about RDDs or shuffles. Its job is mechanical:
- Take each TaskSet from the DAGScheduler
- Work with the SchedulerBackend to request executors and figure out where tasks can run
- Assign tasks to executors, trying to keep them close to their data (see below) whenever possible.
- Retry failed tasks when necessary
If an executor dies or a task throws an exception, the TaskScheduler resubmits the task to another executor, respecting Spark's task locality preferences — keeping tasks close to where the data resides whenever possible.
This handoff — DAGScheduler to TaskScheduler — is what converts a logical plan into a physical reality running across the cluster. Where the DAGScheduler thinks in stages, the TaskScheduler works in terms of executors and available CPU cores — the slots where tasks will run. It speaks the language of threads, resources, and task placement.
All that being said, TaskScheduler itself does not launch tasks. It hands them to the SchedulerBackend.
SchedulerBackend
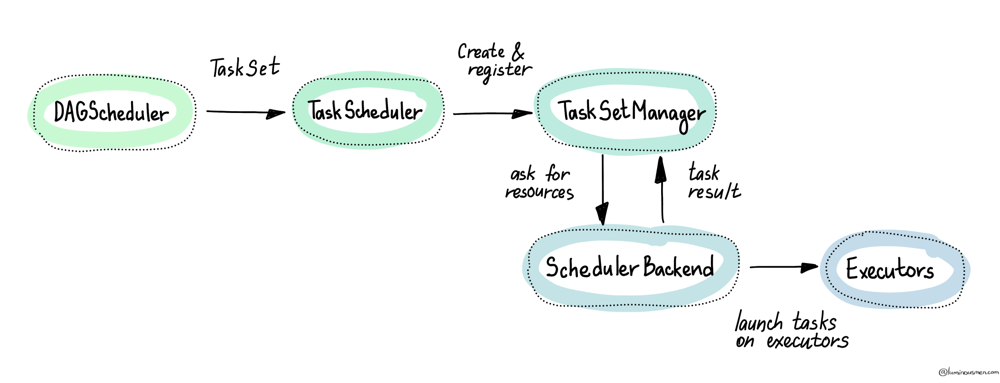
Underneath the TaskScheduler lives the SchedulerBackend. The SchedulerBackend is the messenger between Spark and the cluster manager. It doesn't understand DAGs or stages — it just deals in resource requests and executor lifecycle management.
Its responsibilities include:
- Talking to the cluster manager to request new executors
- Launching and killing executors as needed
- Reporting executor availability back to the TaskScheduler
When you see Spark dynamically scale executors up and down during a job, that's the SchedulerBackend negotiating with the cluster manager behind the scenes.
BlockManagerMaster
While above schedulers focus on when and where tasks run, the BlockManager is all about the data those tasks need.
Spark processes everything as partitions, and each partition becomes a block stored either in memory or on disk. And every RDD partition, every shuffle file, every broadcast variable goes through the BlockManager. When an executor needs a block of data, the BlockManager either hands it over locally or fetches it from a neighbor.
Every executor has its own BlockManager, but the Driver hosts the BlockManagerMaster, which keeps a global map of all block locations across the cluster. Whenever a task needs a block, the BlockManager can serve it directly if it's local, or fetch it from a remote executor if necessary. This is the mechanism that makes shuffles, caching, and recomputation possible.
BlockManager handles:
- Storage and retrieval of blocks in memory or on disk
- Replication for fault tolerance, so losing one executor doesn't mean losing the only copy of a partition
- Data exchange between executors during shuffles or when fetching cached partitions
It also powers Spark's caching and persistence. When you call cache or persist, the BlockManager decides whether the block stays in memory, spills to disk, or is evicted to make room for new data. This constant juggling is what keeps future stages fast without running out of memory.
If a BlockManager disappears, Spark may need to recompute lost partitions using RDD lineage or fetch replicas from surviving executors. Without this system, Spark would have no awareness of where its data lives, and every shuffle or cached computation would fall apart. Sadly.
Together, these four components turn the Driver from a passive coordinator into a full blown distributed engine. And when they all do their jobs well, you never have to think about them — you just see your Spark job finish.
Spark Context
The Spark Context serves as the primary entry point for all Spark operations, acting as a bridge between the Spark Driver and the cluster's resources. Through the Spark Context, the Driver communicates with the Cluster Resource Manager, requests executors, and coordinates the execution of distributed computations. It's also the mechanism for creating RDDs, managing shared variables and tracking the status of executors via regular heartbeat messages.
Every Spark application operates with its own dedicated Spark Context, instantiated by the Driver when the application is submitted. This context remains active throughout the application's lifecycle, serving as the glue that holds together the distributed components. Once the application completes, the context is terminated, releasing the associated resources.
The modern way to start a Spark application is through a SparkSession, which wraps around the lower-level SparkContext. While the SparkSession gives you access to DataFrames, SQL, and config management in a friendly API, it's the SparkContext underneath that actually drives the core engine — requesting executors, creating RDDs, and coordinating cluster resources. You can think of SparkSession as the front desk, and SparkContext as the operations center.
Cluster Resource Manager
In a distributed Spark application, the Cluster Resource Manager (or Resource Manager for short) is the component responsible for allocating compute resources across the cluster. Depending on your deployment, this could be YARN, Kubernetes, or Spark's own standalone cluster manager.
When a Spark application starts, the Driver requests executor resources via the SchedulerBackend, which then communicates with the Cluster Resource Manager. Based on available capacity and scheduling policies, the cluster manager launches executor processes on worker nodes — in containers, pods, or raw processes, depending on the setup.
Once executors are up, they register back with the Driver, and the Driver begins assigning tasks to them. From that point on, the cluster manager's job is mostly done — it keeps the executors running and watches for node failures, while Spark handles the actual data processing.
The SparkContext is the Driver's interface to the cluster manager. It abstracts the differences between backends and lets your application scale across environments without changing your code.
Executors
Executors are the backbone of a Spark application, running on worker nodes to execute tasks assigned by the Driver. These processes handle the actual data processing and data storage.
By default, executors are allocated statically, meaning their number remains fixed for the duration of the application. However, Spark also supports dynamic allocation, where executors can be added or removed to adapt to workload changes. While this flexibility can optimize resource utilization, it may affect other running applications and introduce contention with other applications sharing the same cluster.
In addition to task execution, executors manage data storage. They use the BlockManager to store intermediate RDD data, which can be cached in-memory for quick access or spilled to disk when memory is insufficient (using localCheckpoint).
Spark Application Running Steps
This is a premium deep-dive
You just read the free excerpt. The full analysis continues on Substack.
Read full article → Or subscribe to get all premium posts