
Cluster Managers for Apache Spark: from YARN to Kubernetes
Spark has become the go-to framework for big data processing, and for good reason: it's fast, versatile, and (once you get the hang of it) surprisingly elegant. But mastering it? That's a whole other story. Spark is packed with features and an architecture that feels simple on the surface but quickly grows in complexity. If you've ever struggled with long shuffles, weird partitioning issues, or mysterious memory errors, you know exactly what I mean.
This article is the first in a series on Apache Spark — created to help you get past the basics and into the real nuts and bolts of how it works, and how to make it work for you.
Other articles in the series:
What is Spark?
Think of splitting your laptop into a thousand tiny replicas, each with its own RAM, then running .groupBy().sum() across billions of events.
That, in spirit, is Apache Spark.
Apache Spark is an open‑source cluster‑computing engine built to handle both batch and streaming workloads with an unapologetic focus on speed. It keeps data in memory whenever possible, spilling to disk only when datasets outgrow RAM. Add concise APIs in Scala, Python, Java, and SQL, and engineers get a tool that feels as productive as a notebook but scales to a data‑center.
Beyond language support and in‑memory execution, Spark brings two other pillars that matter day‑to‑day:
- Lazy evaluation. Transformations are recorded as a directed acyclic graph (DAG) and executed only when an action forces a result, letting Spark optimize the entire plan.
- Resilience. The same lineage graph allows partitions to be recomputed on another machine if a node dies, keeping long jobs from collapsing.
Yet for all its intelligence, Spark intentionally stays out of one debate: where your code should run. It simply declares, "Give me 80 executors, each with 4 vCPU and 8 GB RAM, plus a driver". Choosing the actual hosts, allocating resources, and recovering from failure is the job of a cluster manager. But before we meet those managers, let’s rewind to the platform that made space for them.
The Evolution of Hadoop
In 2006, Yahoo! turned Google’s MapReduce research project into an open-source reality and called the result Hadoop. Release 0.x shipped two core pieces:
- HDFS (Hadoop Distributed File System) – a block-based, write-once distributed file system tuned for high-throughput, sequential I/O on clusters of commodity servers.
- MapReduce – a batch-processing engine that runs every job through three canonical phases: map → distributed shuffle → reduce.
For the Big Data world, this was a revelation — terabytes could now be processed on racks of cheap servers instead of specific premium hardware.
The next major revision, Hadoop 2 introduced a third component: YARN (Yet Another Resource Negotiator). YARN split resource management out of MapReduce and became a cluster‑wide operating system, handing out CPU and memory to any engine that asked politely. With YARN in place, processing engines like Spark, Tez, and Flink could run and flourish side-by-side on the same platform without touching Hadoop’s storage layer. That decoupling is what let Spark catch fire inside existing Hadoop deployments.
Why Spark Won
So, why did Spark become such a go-to tool for big data processing?
One word: speed.

While MapReduce relies heavily on disk I/O — writing data to disk between each processing phase — Spark uses in-memory computing to keep data in RAM throughout the computation and spill to disk only when necessary. By explicitly caching or persisting an RDD/DataFrame, Spark dramatically increased processing speed, especially for iterative algorithms that need to access the same data multiple times. This shift from disk-based to in-memory processing makes Spark not just faster, but also more suitable for applications that require near real-time analytics or iterative machine learning models, which MapReduce struggles to handle efficiently.
On top of that, Spark’s friendy API (all cool stuff like Scala’s chained functions, Python’s lazy DataFrames, ANSI‑compliant SQL) makes it a framework that’s not just useful, but one data engineers want to use. We prefer tools that minimize cognitive overhead so we can focus on solving problems, not wrestling with syntax, right?
Lastly, Spark is poly-modal — batch ETL is built in, real-time pipelines can ride on Spark Structured Streaming, and machine-learning workloads plug straight into MLlib — all powered by the same execution engine.
Power and usability made engineers reach for Spark — as long as their jobs could find a slot to run. Leaving the comfort of a single machine means you still need a data‑center operating system that decides where each executor lands and how to restart it after failure. That’s the job for cluster managers — YARN in the Hadoop world, Kubernetes in the container era, and a few others along the way.
Cluster Managers 101
To understand where YARN — and later Kubernetes — fit into the picture, let’s borrow a metaphor from everyday computing.
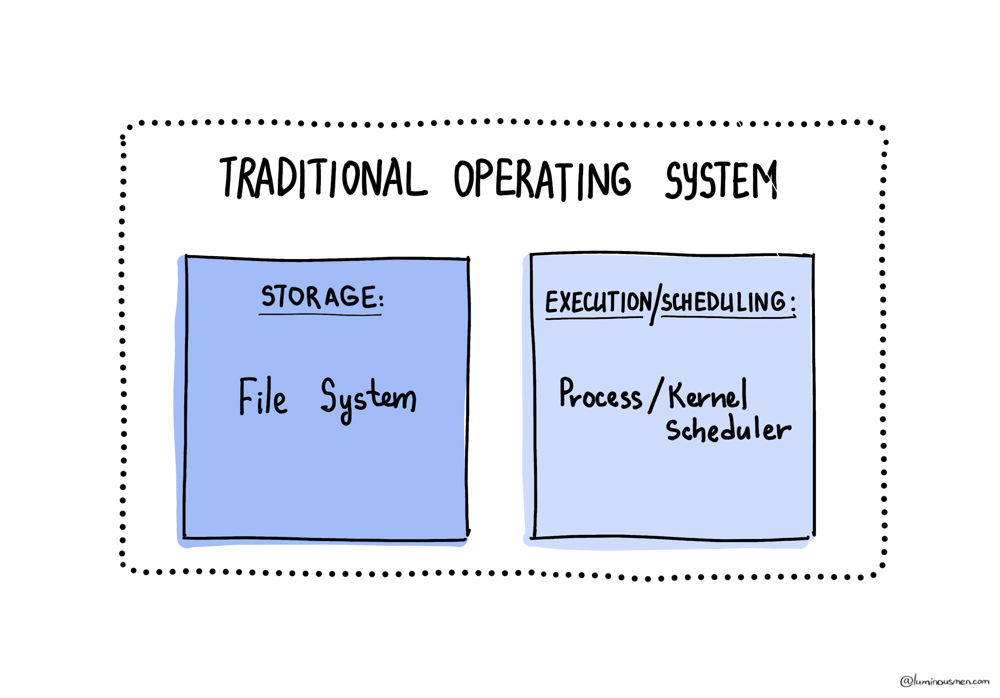
A single machine’s operating system does roughly two big jobs:
- File System: Manages data storage and retrieval (FAT32, ext4, NTFS, etc).
- Kernel & Scheduler: Decide which processes gets CPU, RAM, and I/O, and when.
When we scale this concept to a cluster level and implement it within Hadoop, we see a similar division. But instead of a single-node file system, Hadoop uses HDFS (Hadoop Distributed File System). YARN provides cluster-level resource negotiation (CPU cores and memory) and launches containers for the application execution.
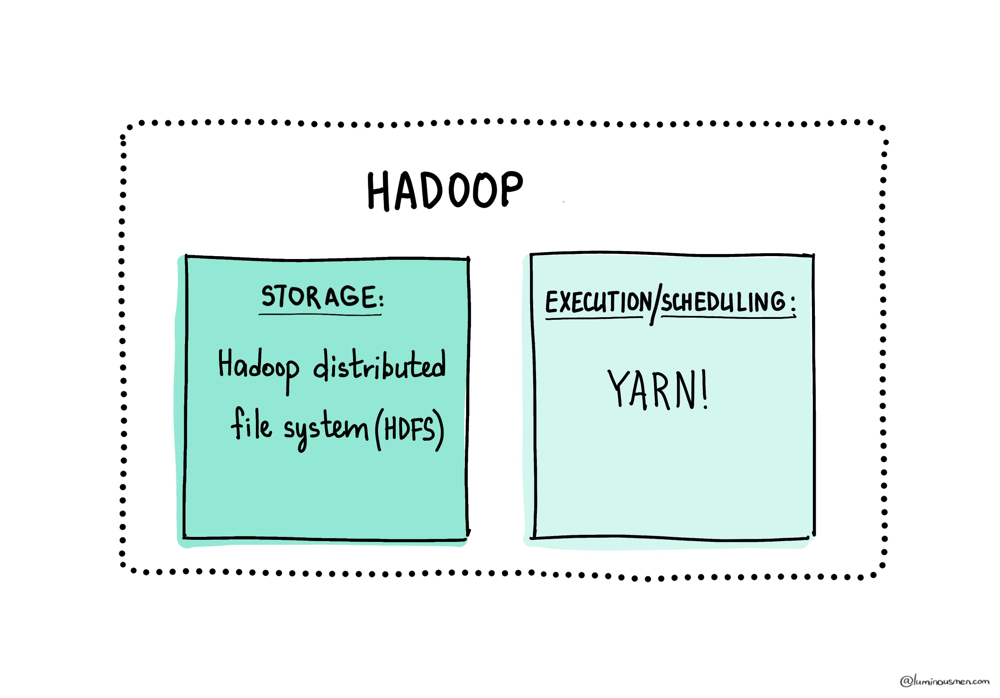
So Spark outsources the "OS"-type management tasks — it’s focusing only on the actual data processing.
Out of the box Spark can speak to:
- Standalone — lightweight scheduler for laptops, CI pipelines, and small proofs‑of‑concept
- Apache Mesos — influential but largely retired now (removed in Spark 3.4).
- YARN — the default in Hadoop‑centric stacks thanks to tight HDFS and Kerberos integration.
- Kubernetes — the default in container‑first organizations which as of now is probably everybody
We deep dive into YARN because it paved the runway for Spark’s early success — and still powers petabytes of production data where HDFS and Hadoop security are non‑negotiable.
Deep Dive into YARN
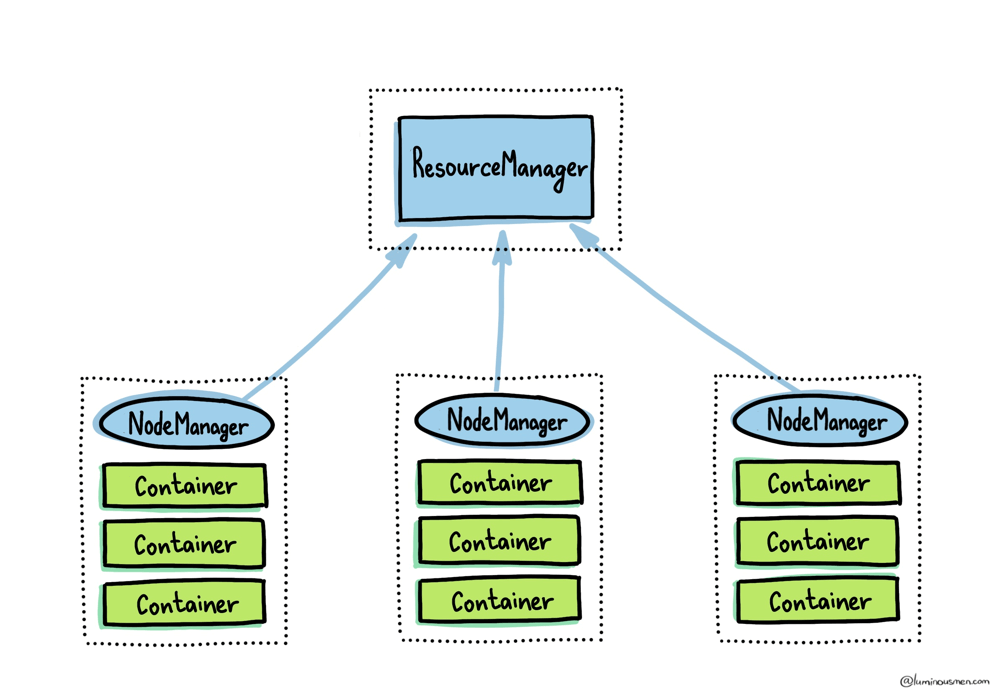
At the heart of YARN sits the ResourceManager. Think of it as the cluster’s traffic controller: every request for CPU or memory, from every application, flows through the ResourceManager first. Nothing starts, scales, or restarts without its say-so.
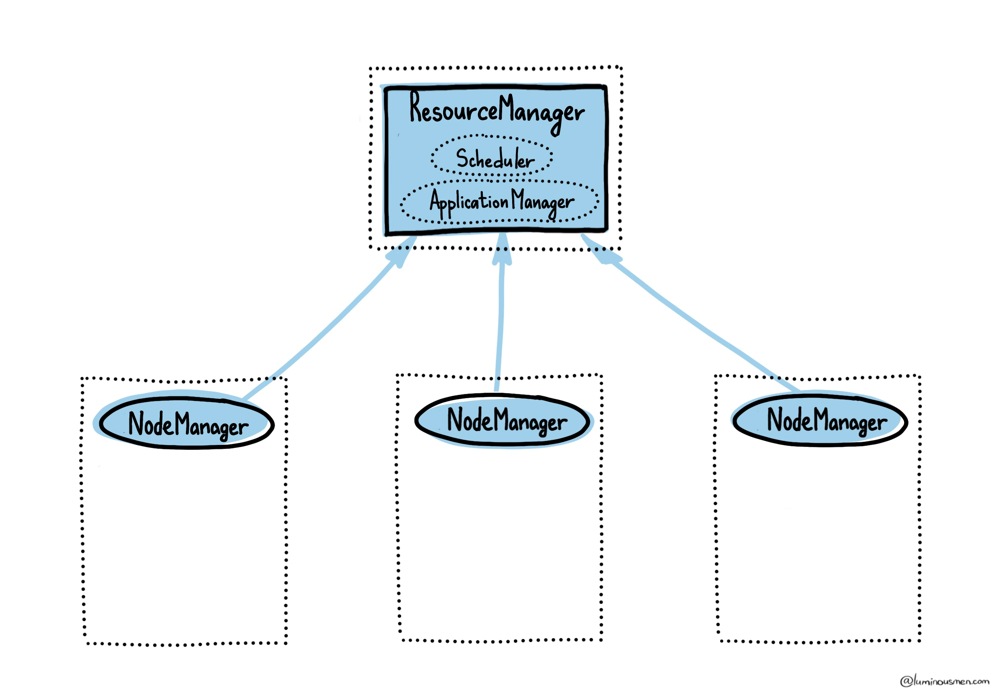
ResourceManager consists of two key services:
- ApplicationManager:
- Accepts and registers new applications
- Manages the application state‑machine (NEW → RUNNING → FINISHED/FAILED/KILLED)
- Requests the first container to launch the ApplicationMaster (described below)
- Scheduler:
Each physical or virtual host in the cluster runs a NodeManager daemon, which reports to the ResourceManager.
Its jobs are straightforward but crucial:
- Launch containers on local Linux cgroups/namespaces
- Monitor the health and resource usage of those containers
- Report status back to the ResourceManager every few seconds (heartbeats)
Each cluster node hosts several Containers (YARN containers), a Container is YARN’s atomic chunk of compute: a slice of memory, a share of vCPUs, plus the environment variables and files the task needs.
Containers are allocated to execute specific tasks for user applications. Their size and configuration can be adjusted based on workload requirements. The size of each container is negotiated at run time.
The NodeManager daemon oversees the containers on its respective node. When a new application is submitted to the cluster, the ResourceManager allocates a container for the ApplicationMaster. The ApplicationMaster job is to negotiate resources with the ResourceManager and coordinates with the NodeManagers to execute and monitor tasks.
Once launched, the ApplicationMaster takes charge of the application lifecycle. Its first task is to send resource requests to the ResourceManager to acquire additional containers for running the application's tasks. Each resource request typically includes:
- The amount of resources needed, specified in terms of memory and CPU shares
- Preferred container locations (like hostname, rack name)
- Priority within the application
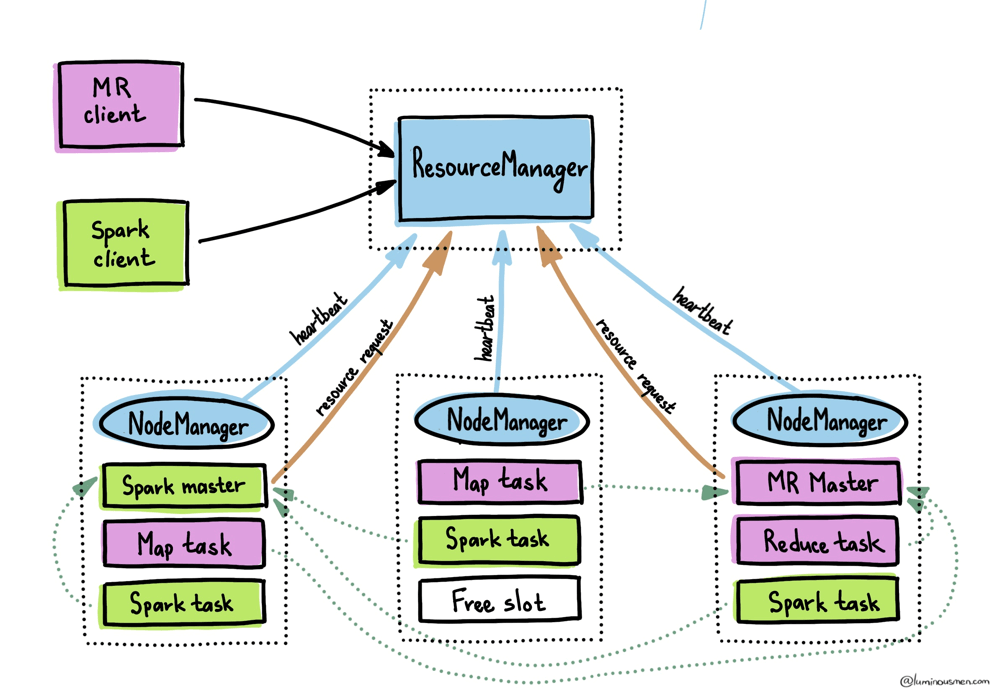
I want to hightlight — the ApplicationMaster runs in a container just like other components of the application. If it crashes or becomes unavailable, the ResourceManager can allocate a new container and restart it, ensuring high availability. The ResourceManager maintains metadata about running applications and task progress in HDFS, so when the ApplicationMaster restarts, it has all the context it needs. This allows the system to recover and restart only incomplete tasks if the application fails.
In this architecture, the ResourceManager, NodeManagers, and containers are framework-agnostic — they don't need to understand the specifics of the application. Instead, the ApplicationMaster handles all framework-specific logic, enabling any distributed framework to run on YARN as long as it provides a suitable ApplicationMaster. We are focused on Spark, but other frameworks can run with YARN as well. Spark executors, Flink tasks, even legacy MapReduce tasks — all of them can run inside YARN containers. This design allows YARN to support a diverse workloads efficiently and flexibly.
Submitting an Application to YARN
When you spark-submit --master yarn, three daemons and a handful of containers jump into action. Here’s the workflow:
- Client (your laptop or CI agent) sends a tiny "launch request" to the cluster’s ResourceManager. The payload says, essentially, "Please start Spark’s ApplicationMaster — here’s the JAR, here’s the memory budget".
- ResourceManager scans its bookkeeping tables, picks a free host, and asks that host’s NodeManager to carve out one fresh container for the ApplicationMaster.
- Inside that container, Spark’s ApplicationMaster starts the JVM, loads your job’s classpath, and registers itself back with the ResourceManager. From this point on, the ApplicationMaster is the single source of truth for everything your job will do.
- Next, the ApplicationMaster requests executor containers from the ResourceManager: "Give me 50 containers, each 4 vCPU/8 GB, preferably close to data on rack A or B". The request can contain multiple sizes and priorities if your job mixes lightweight and heavyweight tasks which is kinda cool.
- The ResourceManager grants containers as capacity frees up. Each chosen NodeManager spins up a new process under cgroups/namespaces, sets environment variables, and hands control to Spark’s executor script.
- Every executor reports back to the ApplicationMaster (which is also the Spark driver) to say, "I’m alive; send work". The ApplicationMaster runs tasks —
map,shuffle,reduce, whatever — while the NodeManagerMs monitor CPU, RAM, and exit codes. - Meanwhile, your spark-submit process (or a web UI) polls the ApplicationMaster for progress: completed stages, failed tasks, shuffle size, you name it. The ApplicationMaster keeps the ResourceManager updated with heartbeat traffic so the job stays visible in cluster dashboards.
- When the application’s last task finishes, the ApplicationMaster tells the ResourceManager, "All done". It writes final counters to HDFS, de-registers, and exits. The ResourceManager then marks remaining containers for garbage collection, and NodeManagers delete logs once retention rules say it’s safe to do so.
In roughly a dozen round-trips and a few seconds of coordination, your Spark job goes from a CLI command to a fully managed, distributed application — ready to process terabytes until the last partition is joined, aggregated, or filtered away all with the help of YARN. Sweet.
Deep Dive into Kubernetes
A decade ago YARN was the obvious companion for Spark — both lived inside the Hadoop ecosystem, both assumed Java everywhere, and both were happiest when HDFS was the only distributed storage. Since then, the center of gravity has shifted. Modern platforms package everything — front-end apps, REST gateways, model servers — into containers and schedule them with Kubernetes.
Interested in the same step-by-step Spark flow — this time on Kubernetes instead of YARN?
🔒 Keep reading by subscribing:
Additional materials
This is a premium deep-dive
You just read the free excerpt. The full analysis continues on Substack.
Read full article → Or subscribe to get all premium posts