Ever had to migrate a petabyte-scale table because you picked the wrong partition key?
No?
Lucky you.
Because when you do, it feels like replacing the foundation of your house while still living in it, except your contractors are raccoons, your floor is lava, and everything's on fire. Fun times.
Partitioning isn't just a checkbox in a database UI. It's one of the most misunderstood and underappreciated design decisions in all of distributed systems. When you get it wrong, you don't just lose performance — you lose control. Of costs. Of reliability. Of observability. Of your sleep schedule.
But before we throw ourselves into the pit of partitioning mistakes, let's rewind a second.
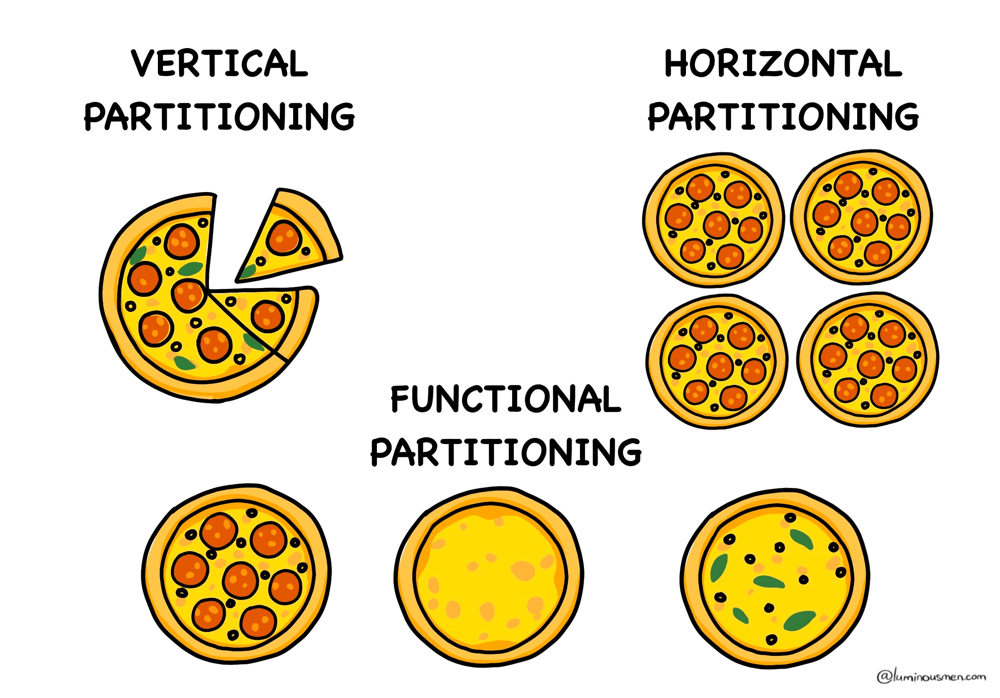
So... What the Hell Is Partitioning?
Let me break it down with something sacred: pizza.
Imagine a big, glorious pizza. Extra cheese, maybe pepperoni. Hungry yet?
Now slice it.
Boom — you just partitioned your pizza.

Each slice is still pizza, obviously — but it's not the whole pizza. Just like in data: you've taken a single big dataset and chopped it into smaller, more manageable chunks called partitions.
Partitioning is about taking your massive, bloated, million-row-per-minute data stream and breaking it down into chunks that can be:
- Queried faster
- Stored smarter
- Scaled better
- And debugged without developing stress hives
When your data is a single monolithic blob, every query becomes a full-table scan and every update is a performance nightmare. But when you chop it up — strategically — you unlock concurrency, isolation, and actual sleep.
And no, partitioning isn't just a "database thing". Partitioning is everywhere — object storage, distributed computing, message queues, logs, analytical platforms. If you're dealing with data at scale, you're already dealing with partitioning, whether you realize it or not.
Types of Partitioning
There are no right or wrong partitioning strategies sadly. You've got options — and like most things in engineering, the right choice depends on your use case (and pain tolerance).
Vertical Partitioning
Vertical partitioning separates frequently accessed columns from the rarely used ones. The goal is to reduce query execution time by minimizing the amount of data retrieved.
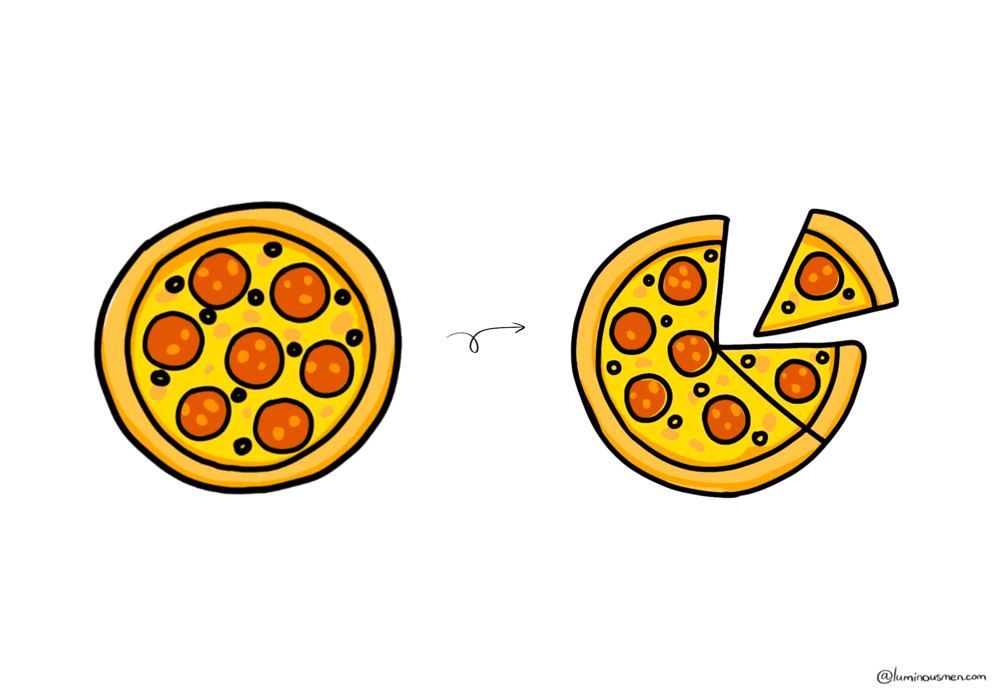
Let's consider your phone's contact list, as an example. For each person, you might store:
- Name
- Phone number
- Birthday
- Home address
- Notes
- Profile pic
- Bio text
- Social media links
- Favorite dog breed
Now... 99% of the time, when you scroll or search, all you actually care about is:
- Name
- Phone number
- Maybe profile pic
But if every single time your phone had to load all the fields — including those big photos, addresses, and bio text — just to show you "Benjie - Mobile", it'd be slow and wasteful.
It's basically data normalization, but with performance in mind:
- Reduced I/O: Only grab the columns your query actually needs.
- Lower lock contention: Writes to one partition don't block reads from another.
- Scalable: You can separately optimize and scale hot and cold data.
Use this when:
- Your tables are wide (think dozens or hundreds of columns).
- Most queries only touch a small subset of columns.
- You're running into I/O bottlenecks from scanning bulky, unnecessary data.
- You're trying to squeeze more performance from a read-heavy workload without going full denormalization.
Horizontal Partitioning
A data engineer's bread and butter. Or maybe their weekly migraine.
Horizontal partitioning is where you split your rows based on some key — time, ID, region, blood type — and stash them in separate buckets. You're not breaking up the schema like with vertical partitioning. You're slicing the data itself.
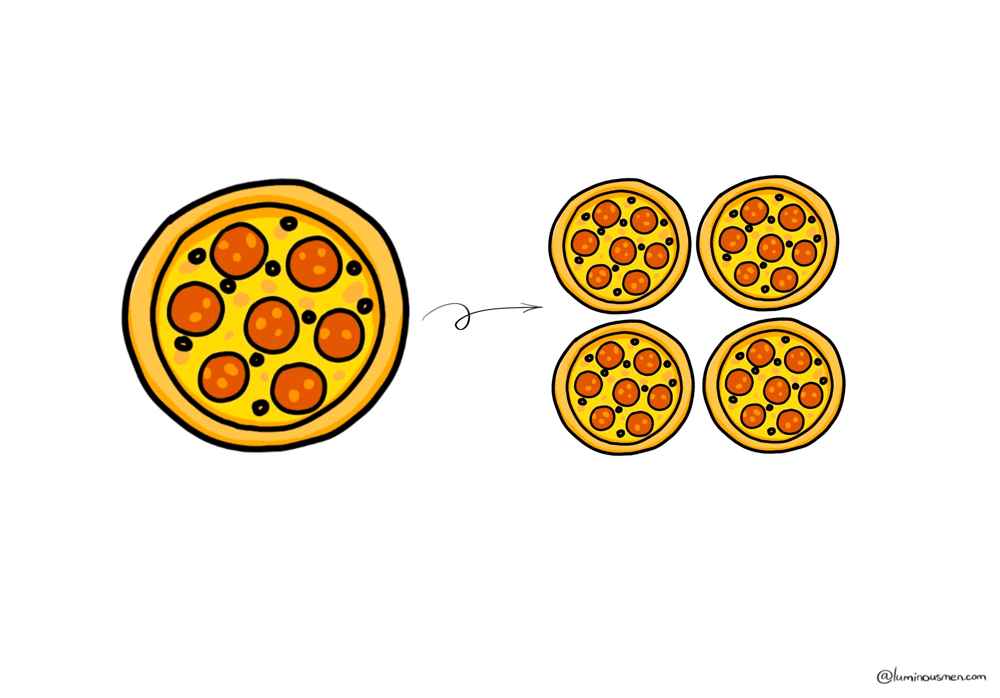
For example this range-based partitioning by user_id:
user_id 1–10M → Partition A
user_id 10M–20M → Partition B
...
Each partition contains a subset of rows from the full table divided based on the partitioning key. You're not splitting the schema, you're slicing the data horizontally — every partition has the same columns, just different rows. This way, your system doesn't try to cram all 2 billion rows into RAM every time someone runs a query.
And once those partitions live on different machines or databases, it's not just partitioning anymore — it's sharding.
Sharding
Partitioning is logical. Sharding is physical.
Sharding is horizontal partitioning done across distributed infrastructure. Each shard becomes its own little universe — isolated storage, isolated compute, and isolated failure domain. It comes with routing logic, replication, cross-shard queries, and a mild existential crisis when you realize your shard key doesn't scale.
You don't have to shard. But if your dataset gets big enough, or your infra creaks under load, you might not have a choice.
Use this when:
- You're working with large datasets that grow fast — time-series data, logs, users, events.
- You need horizontal scaling to distribute load or manage operational limits.
- You want to run queries in parallel without bottlenecking on a single chunk of data.
- You're building on top of infrastructure like BigQuery, Hive, or Spark — where partitioning isn't optional, it's survival.
Functional Partitioning
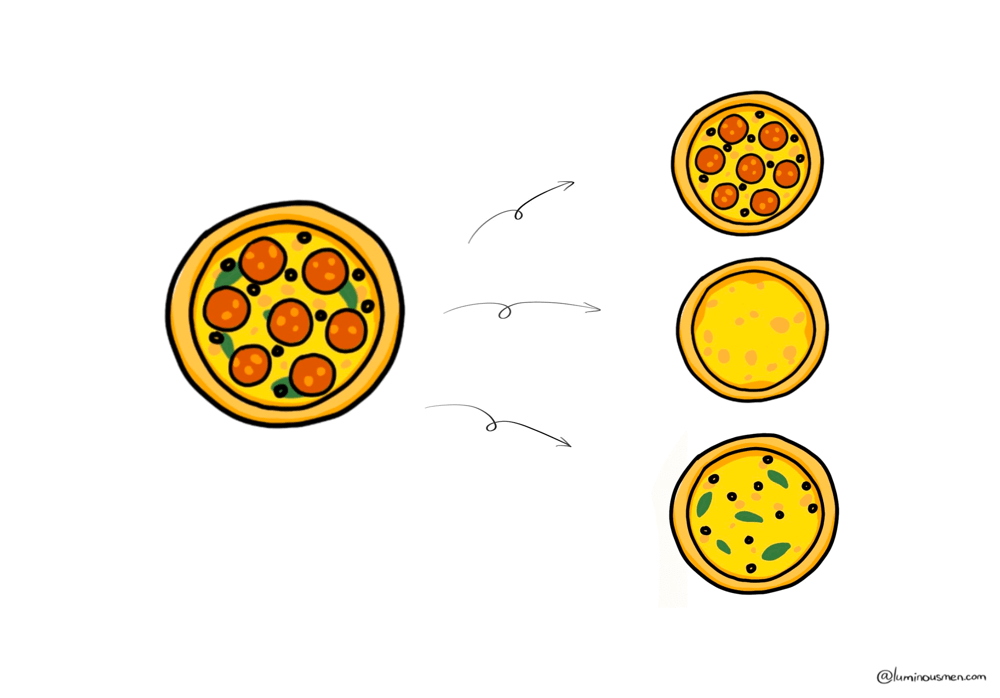
Forget rows or columns — this one's about boundaries that matter. Not technical ones. Business ones.
Functional partitioning means you split your data not by rows or columns, but by function. As in, different domains of the business get their own separate data stores, pipelines, and maybe even tech stacks.
Think domain-driven design, but for your data architecture. You're no longer optimizing queries — you're optimizing organizational clarity, operational independence, and team velocity.
It's not "this table goes here because it has these columns". It's "this data lives here because it belongs to this function of the business".
It's like having separate kitchens in a restaurant — hot food, desserts, drinks. Each partition serves a specific business function:
- Transactions → Stored in a transactional DB (Postgres, Cockroach, whatever keeps you honest).
- User Profiles → Redis, DynamoDB, or something that can answer "who is this user" in 3 ms flat.
- Analytics Logs → S3, Delta Lake, or a Kafka-backed pipeline dumping JSON at terrifying rates.
- Product Catalog → Probably a document store or search-optimized engine (Elastic, Mongo, whatever).
Each system is partitioned by purpose, not schema. You don't ask the OLTP (Online Transactional Processing) database for analytics metrics. You don't dump user logs into your CRM. Each piece lives in its own sandbox.
Why? Because this scales. Not just technically, but — organizationally.
This approach aligns with Conway's Law: your architecture ends up looking like your org chart. So you might as well lean into it and design accordingly.
And yeah, your data ends up scattered across services, lakes, queues, and maybe a few Postgres instances nobody wants to admit still exist. But it's worth it — because now each piece can evolve on its own timeline. And that's how real systems grow without imploding.
Why? Because this scales. Not just technically — organizationally.
Use this when:
- Your system naturally splits into domains.
- You want to scale teams without turning every schema change into a cross-team negotiation.
- You're sick of blending analytics, product, and user data into one monolith that's slow, brittle, and hated by everyone.
Data Skew
Like pizza slices, partitioning is not always fair. Some slices are bigger, some smaller. Some have more toppings, others less. A few unlucky ones might end up all crust. That's your uneven partition distribution in a nutshell — also known as data skew.
Data skew happens when your partitioning strategy unintentionally stuffs 90% of the data into 10% of the partitions. As a result, some machines are sweating buckets while others are chilling. Your job runs slow, your costs go up, and you start thinking maybe you should have gone into sales.
Why does it happen?
- You picked a low-cardinality key (
country_code,gender, etc) - You hashed a field that looked random but wasn't
- You're logging events and one service is extremely chatty
How to fight it:
- Salting: Add noise to your keys. Random suffixes like
user_id + rand(5)can help spread stuff around. - Bucketing: Use bucketing functions to enforce even splits. Useful in Hive/Spark where random splits can lead to skewed partitions—bucketing hashes keys into fixed buckets, giving you repeatable and balanced data slices.
Bucketing: Use bucketing functions to enforce even splits by hashing on a specific column (like user_id). This is especially useful in Hive/Spark when you need reproducible data partitioning for things like training/test splits or efficient joins.
- Monitoring: Set up metrics for partition sizes early. Catch skew before your ops team does.
Wrapping It Up
Partitioning is a pain in the ass. But it's also your first line of defense against scaling issues later on. It affects everything —speed, cost, debuggability, team velocity, and even how much your engineers swear during sprint planning.
Partitioning is an architecture, not an optimization. It's the skeleton your entire system hangs on. And no, you don't need to go full monk-mode and reinvent your whole data platform, but you do need to stop treating partitioning like it's a checkbox and start treating it like it's core design work. Because it is.
When was the last time you reviewed your partition strategy? Be honest.