
This is the fourth post in a series on asynchronous programming. The whole series tries to answer a simple question: "What is asynchrony?". In the beginning, when I first started digging into the question, I thought I knew what it was. It turned out that I didn't know the slightest thing about asynchrony. So let's find out!
Whole series:
- Asynchronous programming. Blocking I/O and non-blocking I/O
- Asynchronous programming. Cooperative multitasking
- Asynchronous programming. Await the Future
- Asynchronous programming. Python3.5+
In this post, we will talk about Python stack with the concepts we've talked about so far — synchrony and asynchrony: from threads and processes to the asyncio library.
Asynchronous programming with Python is becoming more and more popular recently. There are many different libraries for performing asynchronous programming on Python. One of these libraries is asyncio, which is a standard library on python added in Python 3.4. On Python 3.5, we got the syntax of async/await.
Asyncio and ASGI are probably one of the reasons why asynchronous programming is becoming more and more popular on Python. In this article, we will tell you what asynchronous programming is and compare some of these libraries.
Quick Recap
What we have realized so far from the previous posts:
- Sync: One thread is assigned to one task and it is de facto locked until the task is completed.
- Async: blocking operation is removed from the main application thread.
- Concurrency: Making progress together.
- Parallelism: Making progress in parallel.
- Parallelism implies Concurrency. But Concurrency does not always mean parallelism.
Python code can mostly be executed in one of the two worlds, synchronous or asynchronous. You should think of them as separate worlds with different libraries and call styles, but with shared use of variables and syntax.
Synchronous world
In the Python synchronous world, which has been around for decades, you call functions directly, and everything is handled consistently, exactly as you wrote it.
In this post, we will compare different implementations of the same code. We will try to implement two functions. The first one is calculating the power of a number:
def cpu_bound(a, b):
return a ** b
We will do it N times:
def simple_1(N, a, b):
for i in range(N):
cpu_bound(a, b)
And the second is download some data from the internet:
def io_bound(urls):
data = []
for url in urls:
data.append(urlopen(url).read())
return data
def simple_2(N, urls):
for i in range(N):
io_bound(urls)
To compare how long the function has been running, we will implement a simple decorator/context manager to measure time:
import time
from contextlib import ContextDecorator
class timeit(object):
def __call__(self, f):
@functools.wraps(f)
def decorated(*args, **kwds):
with self:
return f(*args, **kwds)
return decorated
def __enter__(self):
self.start_time = time.time()
def __exit__(self, *args, **kw):
elapsed = time.time() - self.start_time
print("{:.3} sec".format(elapsed))
Now let's put it all together and run it to see how long my machine will execute this code:
import time
import functools
from urllib.request import urlopen
from contextlib import ContextDecorator
class timeit(object):
def __call__(self, f):
@functools.wraps(f)
def decorated(*args, **kwds):
with self:
return f(*args, **kwds)
return decorated
def __enter__(self):
self.start_time = time.time()
def __exit__(self, *args, **kw):
elapsed = time.time() - self.start_time
print("{:.3} sec".format(elapsed))
def cpu_bound(a, b):
return a ** b
def io_bound(urls):
data = []
for url in urls:
data.append(urlopen(url).read())
return data
@timeit()
def simple_1(N, a, b):
for i in range(N):
cpu_bound(a, b)
@timeit()
def simple_2(N, urls):
for i in range(N):
io_bound(urls)
if __name__ == '__main__':
a = 7777
b = 200000
urls = [
"http://google.com",
"http://yahoo.com",
"http://linkedin.com",
"http://facebook.com"
]
simple_1(10, a, b)
simple_2(10, urls)
On my hardware, cpu_bound function took 2.18 sec, io_bound — 31.4 sec.
So, we get our baseline. Let's move on to our first approach.
Threads

A thread is the smallest unit of processing that can be performed on the operating system.
The threads of the process can share the memory of the global variables. If the global variable changes in one thread, this change is valid for all threads.
Simply speaking, a thread is a sequence of operations inside a program that can be executed independently from the main thread. Threads that are executed concurrently(using time-division multiplexing) can be executed in parallel — it depends on the system where they are executed.
Python threads are implemented using OS threads in all implementations I know (CPython, PyPy and Jython). Each Python thread has its own underlying OS thread(POSIX threads or Windows threads).
One thread is executed on a single CPU core. It runs until it spends its time (100 ms by default), or until it gives control to the next thread by making a system call.
Let's try to change our functions by using threads:
from threading import Thread
@timeit()
def threaded(n_threads, func, *args):
jobs = []
for i in range(n_threads):
thread = Thread(target=func, args=args)
jobs.append(thread)
# start the threads
for j in jobs:
j.start()
# ensure all of the threads have finished
for j in jobs:
j.join()
if __name__ == '__main__':
...
threaded(10, cpu_bound, a, b)
threaded(10, io_bound, urls)
On my hardware, cpu_bound took 2.47 sec, io_bound — 7.9 sec.
The I/O-bound function is more than 5 times faster as the data are loaded in parallel on separate threads. But why does the work on the CPU-bound function go slower?
The reference implementation Python — CPython contains the infamous GIL (Global Interpreter Lock). And we slowly move to its part...
Global Interpreter Lock (GIL)
First of all, GIL is a lock that must be taken off before any access to the Python runtime (and this is true not only for the Python code execution but also for Python C API calls). Essentially, GIL is a global semaphore that does not allow more than one thread to work simultaneously inside the interpreter.
Strictly speaking, the only call available after starting an interpreter without GIL capturing is its capture. Violation of the rule leads to an instant emergency shutdown (the best option) or delayed shutdown (much worse and more difficult to debug).
How does it work?
When a thread is launched, it performs a GIL capture. After some time the process scheduler decides that the current thread has done enough and transfers control to the next thread. Thread #2 sees that the GIL has been captured, stops working, and goes into sleep mode, yielding the processor to thread #1.
However the thread can't hold GIL indefinitely. Before Python 3.3, GIL used to switch every 100 machine instructions. In later versions of GIL, a thread can be held for no longer than 5 ms. GIL is also released if the thread makes a system call, works with a disk or network (I/O operation).
In fact, GIL in the Python language makes useless the idea of using threads for parallelism in computational tasks (operations related to the CPU). They will work sequentially even on a multi-processor system. When performing tasks related to CPU, the program will not speed up but only slows down because now the threads will have to share the processor's time and spend time on switching the processor's context. At the same time, the performance of I/O will not slow down as the threads will release GIL before any I/O operation.
It is clear that GIL slows down the execution of our CPU-bound program by creating threads, capturing and releasing the semaphore itself, and saving the context. But we should note that GIL does not limit parallel execution.
GIL is not part of the language and does not exist in all language implementations, but only in the above mentioned CPython.
So why does it exist at all?
GIL protects existing data structures from concurrent access problems. For example, it prevents the race condition when the object reference counter changes. GIL allows you to easily integrate non-thread safe libraries. With GIL we have lots of fast modules and bindings for almost everything. Maybe GIL is one of the reasons the Python is so popular after all.
GIL control mechanism is available for libraries in C if you need to speed up your computation and want to work on a low level. For example, NumPy releases it on long-running operations. Or, when using the numba package, the programmer can control the disconnection of the semaphore.
On this sad note, you can come to the conclusion that threads will be enough for parallelizing tasks that are bound to I/O. But computational tasks must be performed in separate processes.
Processes
From the OS point of view, a process is a data structure that contains a memory space and some other resources, such as files opened by it.
Often a process has one thread called main thread, but the program can create any number of threads. In the beginning, a thread does not allocate individual resources, instead, it uses memory and the resources of the process that generated it. Because of this, threads can start and stop quickly.
Multi-tasking is handled by the scheduler, part of the operating system kernel, which in turn loads execution threads into the CPU.
Like threads, processes are always executed concurrently but they can also run in parallel, depending on the hardware.
Process implementation:
from multiprocessing import Process
@timeit()
def multiprocessed(n_threads, func, *args):
processes = []
for i in range(n_threads):
p = Process(target=func, args=args)
processes.append(p)
# start the processes
for p in processes:
p.start()
# ensure all processes have finished execution
for p in processes:
p.join()
if __name__ == '__main__':
...
multiprocessed(10, cpu_bound, a, b)
multiprocessed(10, io_bound, urls)
On my hardware, cpu_bound took 1.12 sec, io_bound — 7.22 sec.
Thus, the calculation operation is faster than a threaded implementation because now we are not stuck in a GIL capturing, but the I/O binding function took a little longer because the processes are heavier than threads.
Asynchronous world
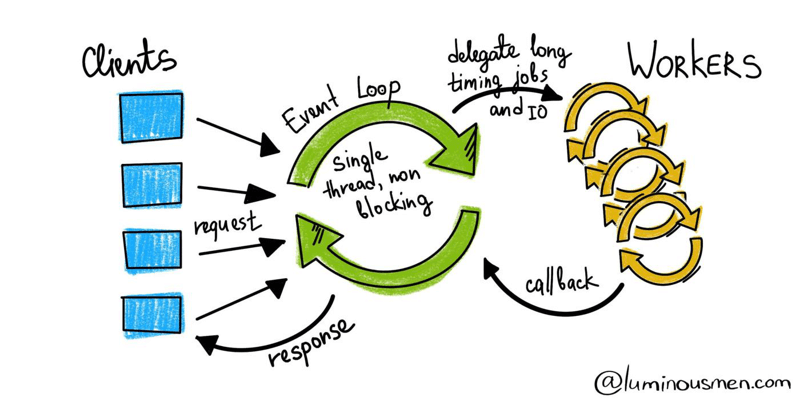
In the asynchronous world, things change a little. Everything starts in the event loop, which is a small code that allows you to run several coroutines at the same time. Coroutines work synchronously until the expected result is achieved and then they stop, transfer control to the event loop where something else might happen.
Green threads

Green threads is a primitive level of asynchronous programming. A green thread is a normal thread except that switching between logical threads takes place in the application code (at the user-level) and not at the operating system level.
Gevent is a well-known Python library that implements green threads. Gevent is a green thread and does not block I/O. gevent.monkey monkey-patches the behavior of standard Python libraries so that they allow non-blocking I/O operations.
Other libraries:
Let's see how performance will change if we start using green threads with the gevent library on Python:
import gevent.monkey
# patch any other imported module that has a blocking code in it
# to make it asynchronous.
gevent.monkey.patch_all()
@timeit()
def green_threaded(n_threads, func, *args):
jobs = []
for i in range(n_threads):
jobs.append(gevent.spawn(func, *args))
# ensure all jobs have finished execution
gevent.wait(jobs)
if __name__ == '__main__:
...
green_threaded(10, cpu_bound, a, b)
green_threaded(10, io_bound, urls)
Results are: cpu_bound — 2.23 sec, io_bound — 6.85 sec.
Slower for CPU-bound function, and faster for I/O-bound function. As expected.
Asyncio
Package asyncio is described in Python documentation as a library for writing concurrent code. But asyncio is not multithreading and is not multiprocessing. It does not build over one of them.
While Gevent and Twisted seek to be high-level frameworks, asyncio seeks to be a low-level implementation of an asynchronous event loop, with the intention that high-level frameworks such as Twisted, Gevent or Tornado will be built on top of it. However, it is itself a suitable framework.
In fact, asyncio is a single thread, single process project: it uses cooperative multitasking with Proactor pattern. asyncio allows us to write asynchronous cooperative programs working in one thread using event loop for planning tasks and multiplexing I/O through sockets (and other resources).
How it works
Synchronous and asynchronous functions/calls are different — you can't just mix them. If you lock coroutine synchronously — maybe you use time.sleep(10) instead of await asyncio.sleep(10) — you do not return control to the event loop — the whole process will be blocked.
You should think that your codebase consists of pieces of either synchronous code or asynchronous code — everything inside async def is asynchronous code, everything else (including the main body of the file or Python class) is synchronous code.

The idea is very simple. There is an event loop and we have an asynchronous function in Python. You declare it with async def which changes the behavior of its call. Specifically, the call will immediately return the coroutine object, which basically says, "I can run the coroutine and return a result when you await me".
We pass these functions to the event loop and ask it to run them for us. The event loop returns us a "future" object, it's like promising that I'll get something back in the future but now I'm busy. We keep the promise, time to time checking if it has value (when we feel impatient) and finally when the future has value, we use it in other operations.
When you call await, the function gets suspended while whatever you asked to wait on happens, and then when it's finished, the event loop will wake the function up again and resume it from the await call, passing any result out. Example:
import asyncio
async def say(what, when):
await asyncio.sleep(when)
print(what)
loop = asyncio.get_event_loop()
loop.run_until_complete(say('hello world', 1))
loop.close()
In the example here, the say() function pauses and gives back control to the event loop, which sees that sleep needs to be run and calls it. Then, those calls get suspended with a marker to resume them in one second. Once they resume, say returns a result. After say is completed the main thread ready to run again and the event loop resumes with the returned value.
Only when we call loop.run_until_completed the event loop starts executing all the coroutines that have been added to the loop. loop.run_until_completed will block your program until the Future you gave as an argument is completed.
This is how asynchronous code can have so many things happening at once — anything that's blocking calls await, and gets put onto the event loop's list of paused coroutines so that something else could run. Everything that's paused has an associated callback that will wake it up again — some is time-based, some is event-based, and most of them are like the example above and waiting for a result from another coroutine.
Let's return to our example. We have two blocking functions cpu_bound and io_bound. As I said, we cannot mix synchronous and asynchronous operations — we must make all of them asynchronous. Naturally, not for everything, there are asynchronous libraries. Some of the code remains blocking, and it must somehow be run so that it does not block our event loop. For this, there is a good run_in_executor() method, which runs what we passed to it in one of the threads of the built-in pool without blocking the main thread with the event loop. We will use this functionality for our CPU-bound function. We will rewrite the I/O-bound function completely to await those moments where we are waiting for an event.
import asyncio
import aiohttp
async def async_func(N, func, *args):
coros = [func(*args) for _ in range(N)]
# run awaitable objects concurrently
await asyncio.gather(*coros)
async def a_cpu_bound(a, b):
result = await loop.run_in_executor(None, cpu_bound, a, b)
return result
async def a_io_bound(urls):
# create a coroutine function where we will download from individual url
async def download_coroutine(session, url):
async with session.get(url, timeout=10) as response:
await response.text()
# set an aiohttp session and download all our urls
async with aiohttp.ClientSession(loop=loop) as session:
for url in urls:
await download_coroutine(session, url)
if __name__ == '__main__':
...
loop = asyncio.get_event_loop()
with timeit():
loop.run_until_complete(async_func(10, a_cpu_bound, a, b))
with timeit():
loop.run_until_complete(async_func(10, a_io_bound, urls))
Results are: cpu_bound — 2.23 sec, io_bound — 4.37 sec.
Slower for CPU-bound function, and almost twice as fast as the threaded example for I/O-bound function.
Making the Right Choice
- CPU-bound -> multiprocessing
- I/O-bound, fast I/O, Limited Number of Connections -> multithreading
- I/O-bound, slow I/O, many connections -> asyncio
Conclusion
Threads may be easier if you have a typical web application that is independent of external services and a relatively limited number of users for whom response time is predictably short.
Asynchrony is appropriate if the application spends most of its time reading/writing data rather than processing it. For example, you have a lot of slow requests - web sockets, a long pooling, or you have slow external synchronous backends for which you don't know when the requests will be finished.
Synchronous programming is the easiest to start the development of applications. In this approach, the sequential execution of commands is performed. Even with conditional branching, loops and function calls, we think about code from the viewpoint of performing one step at a time.
An asynchronous application behaves in a different way. It still works one step at a time, but the difference is that the system moving forward does not wait for the current execution step to be completed. As a result, we move on to event-driven programming.
asyncio is a great library, and it's great that it was included in the standard Python library. asyncio has already started building an ecosystem (aiohttp, asyncp, etc.) for application development. There are other implementations of the event loop (uvloop, dabeaz/curio, python-trio/trio) and I think after a while asyncio will evolve into an even more powerful tool than it is today.
Check out my book on asynchronous concepts:

Additional materials
- Grokking Concurrency by Kirill Bobrov
- PEP 342
- PEP 492
- Check the old guido's presentation of the asyncio approach.
- Interesting talk of Robert Smallshire "Get to grips with asyncio in Python 3"
- David Beazley talk about getting rid of asyncio
- uvloop - faster event-loop for asyncio
- Some thoughts on asynchronous API design in a post-async/await world