
Data folks argue about architecture for a reason: the trade-offs pay the pager. Warehouse, Lake, Lakehouse, Mesh — each bends cost, governance, complexity, and team shape in different ways.
The big internet is full of slick diagrams and buzzwords. None of that will help you actually choose. So in this post, we're going deep into how these architectures really work, one by one, no fairy tales.
Data Warehouse
Let's start with the original data architecture: the Data Warehouse. This system has been around since the late 1980s. Back then "modern" data engineering involved working on rows of physical servers, and relational databases ruled the land.
At its core, a Data Warehouse is a centralized, read-optimized system designed specifically for querying, reporting, and analytics. It's where your business data goes after it's been cleaned, structured, and denormalized for performance. Unlike operational databases that are built for transactions — fast inserts, updates, deletes — a warehouse is built for OLAP (online analytical processing): aggregations, joins, historical trends, and slow-but-heavy queries.
It was born out of the need to give business users consolidated, analytics-ready data by pulling information from operational databases into a single, centralized repository. Think of it as a high-maintenance archive where every book is meticulously categorized, indexed, and shelved for quick reference.
Key Characteristics
- Schema-on-write: Data is organized into predefined schemas as it enters the warehouse. If the data doesn't fit, either someone's writing an ETL job to make it fit or it's not getting in.
- Optimized for analytics and reporting (OLAP): Built for BI use cases, it delivers fast aggregate queries and supports tools like Tableau and Power BI. Data Warehouses use columnar storage and heavy indexing to make aggregations and joins reasonably fast.
- High data quality and governance: The rigid schema ensures consistent data quality, making it perfect for producing trusted reports and dashboards.
- ACID compliance: Transactions are reliable and consistent, which is critical for ensuring data integrity.
- Relational database-centric (SQL-friendly): Typically focused on storing neatly organized, structured data that plays well with relational models, making it approachable for teams already fluent in SQL.
Use Case
The main reason companies are building Data Warehouses is to realize the need to consolidate data from different systems. This allows users to build and automate reporting without sacrificing performance and without creating chaos from querying data across multiple sources. In fact, a DWH contains analytics and metrics for all areas of the organization, creating a complete information picture.
Hence, the Data Warehouse shines when you're asking known questions about known data. Need to answer "How much revenue did we generate last quarter?" or "What's our customer churn rate?" — no problem. The Data Warehouse gives you fast, accurate results.
Limitations
There are, of course, limitations and trade-offs that should be considered:
- Rigid schemas: Changing a schema is painful, often requiring rework on pipelines and ETL jobs.
- Limited support for unstructured/semi-structured data: JSON, video, or IoT data? Good luck. Most warehouses weren't built for this.
- Expensive to scale: Compute and storage are usually tightly coupled, which means costs can skyrocket as data grows.
- Latency issues: Ingestion needs to interact with the schema-on-write model, which can create delays.
- Vendor lock-in: Many cloud DWHs are proprietary, making the migration painful.
Despite their limitations, the Data Warehouses remains the data center for many organizations. Tools like Snowflake, Google BigQuery, and Amazon Redshift have modernized the concept, introducing elasticity and simplicity. Yet, as data becomes too complex, too diverse, or too vast, structured-only systems start to feel limiting, and new architectures are required.
Data Lake
If the Data Warehouse is a meticulously organized archive, the Data Lake is more like a huge junkyard — or maybe a treasure chest, depending on how you look at it.
Data Lakes were born to address the growing need for flexibility in handling the explosion of semi-structured and unstructured data — things like JSON logs, IoT sensor streams, images, audio, and video. Unlike traditional Data Warehouses, a Data Lake doesn't require a predefined schema, so you can dump in any type of data, regardless of format or structure. The idea is simple: just dump everything into it and figure it out later.
Key Characteristics
- Schema-on-read: Data is stored as-is, and its structure is applied only when you read or query it. This makes it much easier to onboard new data sources without friction. This flexibility is its superpower.
- Support for diverse data: Ideal for diverse data types, from logs to social media feeds to images — no transformation needed upfront. Structured, semi-structured, and unstructured data can coexist — sometimes peacefully, sometimes chaotically.
- Scalable, cost-efficient storage: Built on top of cheap, distributed file systems like Hadoop or cloud object storages (i.e. Amazon S3, Google Storage), it can handle petabytes for cheap.
- ML support: Supports complex analytics and ML use cases by enabling direct access to large volumes of unstructured and semi-structured data.
Use Case
The Data Lake is a centralized repository for raw data of all shapes and sizes, stored in its native format until you decide what to do with it. It's perfect for flexibility and experimentation.
Data Lakes let you experiment, train machine learning models, and explore insights without being boxed in by schema constraints or pre-defined use cases.
Limitations
Don't get too comfortable though. The Data Lake certainly has its downsides:
- Data quality issues (aka Data Swamp): Without governance, the lake can turn into a "data swamp" filled with inconsistent and incomprehensible data. Without proper governance, a Data Lake can quickly turn into a disorganized, unsearchable dumpster fire. (Laugh all you want, but this happens way more often than you'd think).
- Lacks governance and data standardization: The freedom to store everything means managing access, quality, and consistency is harder.
- Complex data retrieval and slower query performance: Scanning raw, unoptimized data can be painfully slow compared to the fast, optimized querying of Data Warehouses.
- Lack of ACID compliance: Transactions are harder to guarantee, which can complicate production pipelines and reliable data workflows.
Despite its challenges, the Data Lake is a powerful architecture for big data processing. But is a Data Lake better than a Data Warehouse? Not exactly. It's more like a sibling with complementary strengths. The Data Warehouse excels at structured, optimized analytics, while the Data Lake thrives on raw, diverse data and experimentation.
What if you want the best of both worlds in one? This is where the Data Lakehouse comes in.
Data Lakehouse
Historically, on-prem Data Warehouses were tightly coupled compute and storage. If your data tripled, so did your hardware bill. Need more storage? Congrats, you're also buying more CPU, even if you don't need it. Efficient? Not even close.
Then the data landscape exploded — not just more data, but more types of data: semi-structured logs, JSONs, images, audio, telemetry, events, you name it. Traditional Warehouses, built for structured, tabular data, simply weren't built to handle that kind of chaos. So people turned to Data Lakes — cheap, scalable storage for everything, regardless of format or schema.
Here's the problem though:
- Data Lakes are great for storing everything, but they're a nightmare to query directly — slow, inconsistent, lacking ACID guarantees, and often with no clear data governance.
- Data Warehouses are great for fast, reliable analytics — but they can't ingest or process raw, messy, or massive-scale data without expensive ETL gymnastics.
So what do you do when one system is flexible but unreliable, and the other is fast but rigid? You build a frankenstack.
Data Lake + Warehouse Architecture
To bridge the gap, many organizations adopted a Data Lake + Warehouse architecture (James Serra in his book calls it Modern Data Warehouse):
- Dump raw, unstructured data into the Data Lake.
- ETL a subset of that data into the Data Warehouse for BI and reporting.
This architecture works and many organizations still rely on it, but it isn't ideal for all use cases. This approach introduced its own issues:
- Double the complexity: Managing a Data Lake and a Data Warehouse isn't just twice the work — it's an exponential increase. Different teams, tools, and philosophies are often required for each layer. It's also a DevOps nightmare.
- Data duplication: The same data often exists in multiple forms: raw in the lake, semi-processed in intermediate storage, and cleansed & transformed in the Data Warehouse. This redundancy increases storage costs and creates governance challenges.
- Latency: That ETL pipeline that I've mentioned between the components? It's a bottleneck. Real-time analytics? Forget about it unless you're investing in costly stream processing solutions. By the time data made it to the warehouse, it's already outdated relative to the raw lake data.
Is there a better way?
What is the Data Lakehouse?
Databricks posed the following question: "Can we turn Data Lakes, based on open formats like Parquet and ORC, into high-performance systems that deliver warehouse-level capabilities and allow direct, fast I/O for advanced analytics?"
They answered it with Data Lakehouse.
The Data Lakehouse combines the flexibility of Data Lakes with the structured power of Data Warehouses. Databricks kicked things off with their Delta Lake and a multi-layered Medallion architecture to transform raw data into structured, analytics-ready formats.
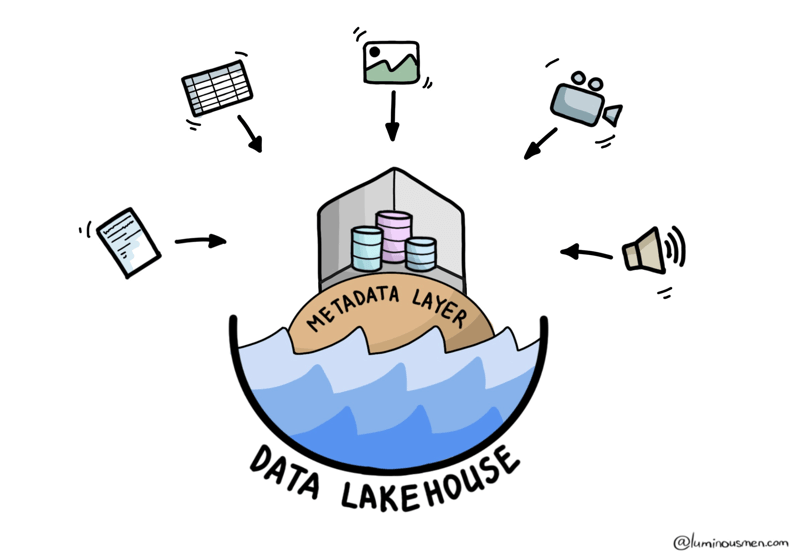
At its core, the Lakehouse is built on a single repository where you can store all types of data (structured, semi-structured, and unstructured) and query it efficiently without sacrificing performance.
This architecture leverages low-cost object storage (like Amazon S3, Azure Data Lake Storage, or HDFS) using a standard file format (like Apache Parquet, Avro, ORC), with an additional transactional metadata layer (aka table format) on top of it to identify which objects belong to which table. The metadata layer allows the implementation of management features such as ACID transactions, data versioning, snapshotting, caching, partition evolution, query optimization, etc while still enabling the benefit of object storage at a low cost.
Key Characteristics
At first glance, the Data Lakehouse may seem like a Data Lake with some additional features. But don't let the name fool you; Data Lakehouses introduce innovations that make it a category apart:
- Unified architecture: Lakehouses use a single storage tier, typically on cheap object storage, but adds structured table formats to make data feel like a Data Warehouse. Technologies such as Apache Hudi, Delta Lake, and Apache Iceberg are often used for this purpose. Lakehouses handle structured, semi-structured, and unstructured data equally well.
- ACID Transactions: Unlike Data Lakes, Lakehouses offer transaction guarantees, so your data pipelines won't break during an update.
- Schema-on-read/write with ACID transactions: Lets you work with raw data (schema-on-read) and also apply transactional updates (schema-on-write) for trusted data.
- Scalable, cost-efficient storage: Built on top of cheap, distributed file systems like Hadoop or now cloud object storages (like Amazon S3, Google Storage), it can handle petabytes while protecting your wallet.
Use case
Imagine a retail company analyzing customer behavior. Your analysts want quick dashboards showing sales trends (classic warehouse use case), while your data scientists want to experiment with product recommendation models using raw click logs and social media data (classic Data Lake use case). Instead of juggling two systems, Data Lakehouses give you one platform to manage them all.
Limitations
Sounds perfect, right? Not so fast.
- Maturity: While technologies like Apache Iceberg and Snowflake's new features are pushing the boundaries, Lakehouses are still evolving. You might see compatibility issues or immature features.
- Complexity: Setting up and managing a Lakehouse can be challenging. You're essentially merging two paradigms, requiring expertise in both.
- Performance may lag compared to purpose-built warehouses: While fast, it may not match the dedicated performance of an enterprise data warehouse for some workloads.
- Cost Tradeoffs: The performance gains when querying raw data don't come for free; you'll likely have to spend more on storage optimization and compute resources.
The Data Lakehouse is a bold concept that continues to gain popularity, especially among companies working with both structured and unstructured data at scale. In my opinion, open formats like Apache Iceberg have significant potential, and we may see more major migrations soon.
Not every organization needs a one-size-fits-all solution though. Some teams prioritize decentralization over unification, which brings us to the Data Mesh.
Data Mesh
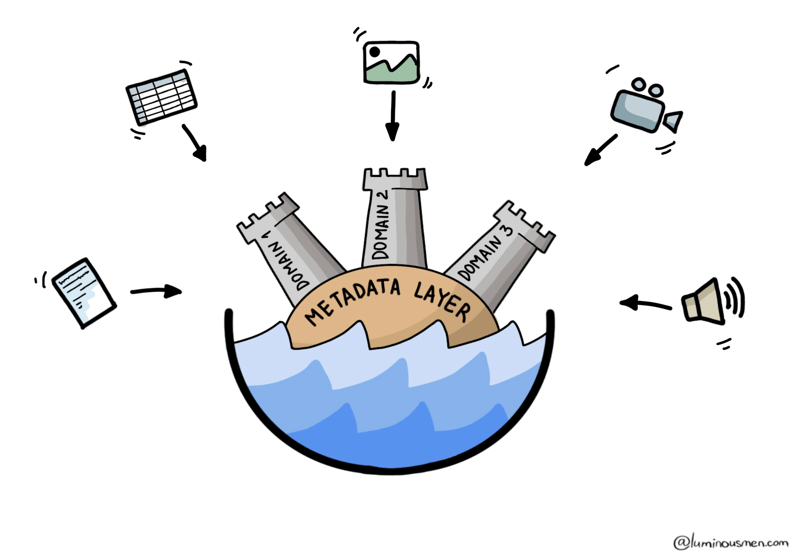
If the Data Lakehouse is a response to technical pain, the Data Mesh is a reaction to organizational pain. It's not a new storage layer or format — it's a shift in how we think about ownership and architecture in large-scale data systems.
Traditionally, we've had central data platforms: one big warehouse, one big lake, one central team that "owns all the data". The idea was to create a single source of truth. Sounds great. Until it doesn't scale. The central team becomes a bottleneck. Domain experts (like Marketing or Ops) have to file Jira tickets just to get a column renamed. Meanwhile, data quality drops because the people managing the data aren't the ones generating or using it day-to-day.
Data Mesh changed this — instead of one central team owning everything, each domain team owns its own data — and treats it like a product.
What does that mean?
- The Marketing team owns their campaign data — they clean it, define its schema, document it, and expose it to others via interfaces.
- The Finance team does the same for budgets, forecasts, and transactions.
- These aren't just tables — they're data products: versioned, discoverable, documented, and governed.
- Other teams can consume these products via APIs, data catalogs, or query layers — without going through a central bottleneck.
Think of Data Mesh not as a tech stack, but as an operating model layered on top of your stack.
So while the Lakehouse tries to merge Lakes and Warehouses into a single unified platform, Data Mesh says: screw unification — let every domain own its piece, as long as they follow the rules.
Key Characteristics
- Decentralized, domain-driven ownership of data: Instead of one central team owning all the data, each domain team is responsible for its data products. Who better to manage data than the teams that understand it best? Think of it as microservices for data.
- Scalability through independent teams: By decentralizing data ownership it allows organizations to scale operations without overwhelming a central data team.
- Data-as-a-product mindset: Data is treated as a product, with an emphasis on usability, quality, and discoverability for other teams.
- Focus on interoperability: Standardized APIs, metadata, and governance rules ensure seamless integration between domains.
Use Case
Let's say you've got dozens of business units: marketing, logistics, supply chain, HR, finance — all with their own engineers, analysts, and data pipelines. And instead of relying on one central team, each domain team becomes responsible for managing their own data products.
It is ideal when:
- Your org is already structured around autonomous product or business teams
- You generate massive volumes of diverse data, and centralized control just doesn't scale
- You're already familiar with DevOps, platform teams, and self-service infra patterns
- You care more about agility, speed, and domain-contextual quality than centralized consistency
In other words: Data Mesh makes sense when your biggest bottleneck is organizational — not technical.
Limitations
- Cultural shift: decentralization requires buy-in and ownership from teams in the field, which can be challenging. Success depends on clear communication, accountability, and buy-in from every team.
- Data Self-Service Infrastructure complexity: Building a self-service platform is non-trivial: it requires investment in tools such as data catalogs, provenance tracking, and automated management. A Data Mesh requires a robust self-service platform that takes care of the complex work of storing, processing, and fulfilling requests so that subject matter experts can focus on delivering value rather than struggling with infrastructure.
- Governance and consistency risks: Decentralization can lead to inconsistent standards if governance isn't robust.
- High initial complexity in design and implementation: Setting up a Data Mesh requires rethinking data architecture and organizational processes, which can be daunting.
Data Meshes are particularly attractive for large, complex organizations with multiple departments generating huge amounts of data. It aligns well with microservices architectures, making it a natural fit for modern, agile engineering cultures.
But a Data Mesh is not for everyone. It works best when teams are mature enough to handle decentralized ownership and have the resources to support self-service infrastructure.The self-service platform is a critical enabler here, if you don't have it you can't implement a Data Mesh.
Collecting All the Pokemons
We've explored the features and limitations of Data Warehouses, Lakes, Lakehouses, and Meshes. Each architecture offers a unique perspective on solving modern data engineering challenges:
- Data Warehouse: excels in structured, high-performance analytics.
- Data Lake: provides flexibility for unstructured and experimental data.
- Data Lakehouse: combines the best of both worlds with unified storage and performance optimization.
- Data Mesh decentralizes ownership, empowering domain teams.
So, which one should you choose?
As with everything in software engineering, it depends. No architecture is a silver bullet. Success often lies not in the technology itself but in how your teams implement and manage it.
Instead of chasing buzzwords, focus on your organization's goals, scale, and maturity. Whether you're modernizing an existing system or building one from scratch, the best architecture is the one that solves the most pressing challenges without adding unnecessary complexity.