
Cue the music. Roll the Gartner slide deck.
Let's talk about something that everyone in data engineering has felt at some point but rarely says out loud: we're being bombarded with marketing BS that's trying to replace actual engineering. You know what I mean.
Every week there's a new "revolutionary" architecture — some AI-powered hammer promising to fix all our problems. And of course, everyone on LinkedIn swears this new thing is the future.
Spoiler: it's not.
Most of it is just rebranded old ideas, overpriced software, or in the best-case scenario thin abstractions over things we've already been doing. In the worst case? Distractions that waste your time, burn your budget, and add complexity without delivering real value.
Let's dig into some of these tools for data engineers — the ones that I'm sick of hearing about. I hope you will convince me that I'm wrong.
Data Fabric
"Data Fabric" sounds like something woven by data elves in the night — a magical tapestry where all your systems are seamlessly connected, metadata flows like lifeblood, and business users get everything they need without ever having to ping engineering again.
Just buy a few licenses from a big vendor, and voilà — all your data problems disappear.
Except... they don't.
So, what is Data Fabric, really?
Behind the buzzword, Data Fabric is just a fancy way of describing a mix of centralized metadata, data virtualization, real-time sync, and a dash of machine learning.
That's it.
On the surface, it sounds amazing:
- No more complex pipelines — everything connects itself!
- Metadata handles everything — no manual work!
- Real-time data access — who needs ETL?
- Self-service for business users — no more Slack discussions!
In practice, though:
- Every connector still needs to be configured, secured, and monitored
- Metadata still has to be collected, cleaned, and constantly updated
- Dirty source data is still dirty — licenses don't scrub data
- Data source behaves differently — there's no magic fix for that
- AI doesn't clean bad inputs — it just guesses faster
- Performance suffers when you try to make everything talk to everything else in real time
All those glowing articles about "data stitching" and "seamless connectivity"? Just creative ways to avoid admitting the obvious: data integration is still hard.
Data Fabric doesn't eliminate these problems; it just moves them around.
This isn't new
Despite what vendors claim, none of this is revolutionary. It's all been done before — we just hadn't given it a shiny name.
- Data virtualization? Been around since the early 2000s
- Metadata/catalogs? Nothing new there.
- Orchestration? We've had those tools for years.
The concepts behind Data Fabric have existed for decades. The only thing that's really new is the branding. And hey — that's fine. Everything's a remix. Just don't pretend it's magic.
Medallion Architecture
If you've worked with data pipelines for more than five minutes, you've already implemented Medallion Architecture... without even knowing it.
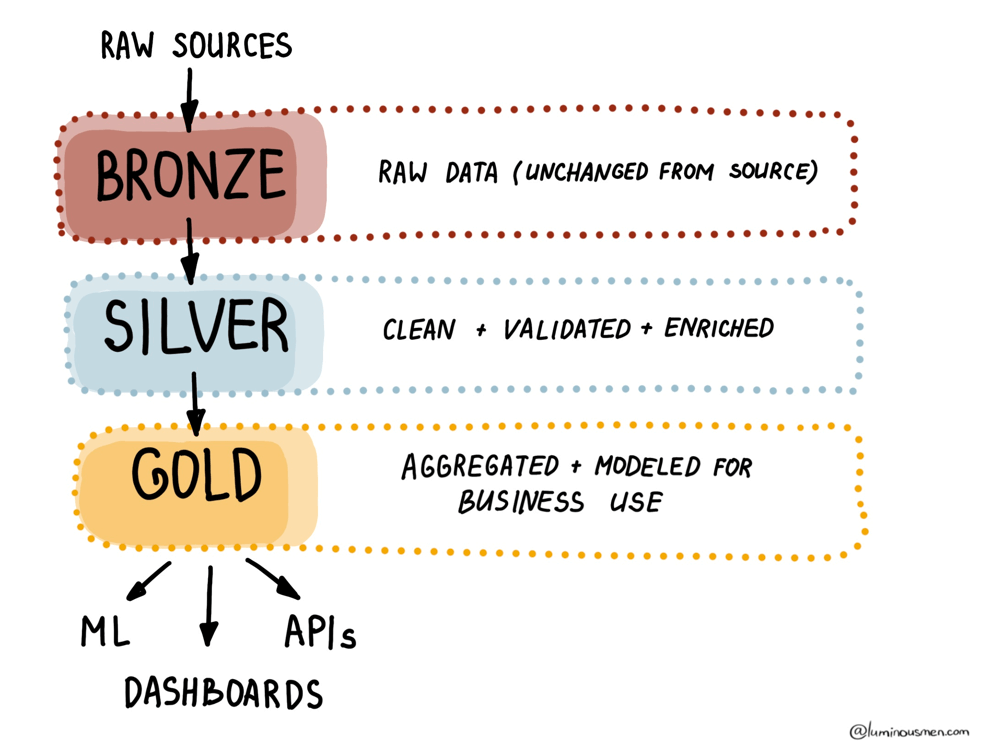
In essence, a Medallion Architecture is a three-layer structure for data pipelines:
- Bronze: Raw, unfiltered data — think of it as the messy data lake.
- Silver: Cleaned and enriched data — basically classic data warehouse layer.
- Gold: Aggregated, analytics-ready data — this is where the dashboards get their goodies.
Sound familiar? That's literally how every sane data system has worked since the dawn of data warehousing.
Here they are as the parallels to some well-known concepts:
-
Inmon – the classic Data Warehouse architecture proposed by Bill Inmon:
- Staging Area (Loading Stage) ≈ Bronze Layer
- CIF (Corporate Information Warehouse) ≈ Silver Layer
- Data Marts (Industry Storage) ≈ Gold Layer
-
Data Vault – a methodology that structures data into three parts:
- Staging Layer for raw stream processing ≈ Bronze Layer
- Raw Vault where the original data is stored ≈ Silver Layer
- Business Vault or Data Marts that transform data into business metrics ≈ Gold Layer
-
Data Mesh – the concept of distributed data ownership:
- Raw Domain Data ≈ Bronze Layer
- Aggregated Domain Data ≈ Silver Layer
- Consumer-Oriented Products ≈ Gold Layer
-
Write-Audit-Publish – a frequently used pattern:
- Write – data collection ≈ Bronze
- Audit – data cleaning and processing ≈ Silver
- Publish – preparing for use ≈ Gold
All these approaches work with the same idea - data goes through multiple layers of processing, from raw state to analytically valuable insights.
Even though the idea isn't original because we slapped some shiny medals on it and said "Delta Lake" three times, now it's a revolutionary framework?
Come on.
The Medallion Architecture isn't new. It isn't magical. It's just... a helpful mental model, with a cool name, that's being oversold like it's DevOps for data. Let's keep things in perspective.
Zero ETL
The reality of every data engineering job on the planet: you move data from point A to point B, clean it up, transform it, and make it usable. That's the job.
That's 90% of what data engineers do. We write pipelines, tune performance, fight lags, and curse ourselves for complex dependencies. That's what makes us data engineers.
Now along comes some product marketer saying, "you don't need ETL anymore. Just connect everything and let the data flow!"
Right. And maybe I'll just vibe my way through schema evolution too.
So, what is ZeroETL?
Zero ETL is the idea that you don't need traditional ETL pipelines anymore. Instead:
- You query or work with data where it already lives — no copying or moving.
- Smart integrations sync data between systems in real-time.
- The data is just... ready to use. Like magic.
With ZeroETL, you'll hear terms like:
- Snowflake External Tables – query cloud storage data directly, no ingestion needed.
- Databricks Delta Sharing – leave data where it is, share access via APIs.
- API-first architectures – microservices hold the data, consumers just query what they need.
In theory, it's brilliant:
Why shuffle data around when you can just access it where it already sits?
Why it sounds too good to be true
On paper, Zero ETL sounds elegant. But in the real world of messy systems and business needs, it breaks down fast for the following reasons:
1. You still have to prep your data
It doesn't matter where your data lives — Snowflake, S3, a microservice — it still needs to be:
- Cleaned
- Unified
- Transformed
- Aggregated
Got duplicate records? You still need to dedupe.
Got inconsistent date formats? You still need to normalize them.
Want to build KPIs or business dashboards? You'll be writing transformations.
And who's going to do that work? You are. Because business can't run on raw spaghetti data.
2. Zero ETL ≠ Zero Engineering
Zero ETL doesn't remove engineering — it just shifts the workload elsewhere.
- Instead of pipelines, you're wiring up complex real-time integrations.
- Streaming tools like Kafka, Kinesis, or Pub/Sub don't configure themselves
- Schema drift, late-arriving data, retries, and deduplication all still happen
- When something breaks at 2 AM, you won't get to say, "but we're Zero ETL" — you'll be fixing it just like before
Real-time isn't magic. It's just a different flavor of complexity.
3. It only works in very specific cases
Zero ETL can work — but usually only in narrow, controlled environments, such as:
- When your entire stack lives inside a single ecosystem (like Databricks or Snowflake)
- When you're dealing exclusively with real-time data
- When your consumers are okay with raw or lightly processed data
But in real life:
- Data is scattered across multiple systems — CRM in Salesforce, finance in SAP, product analytics in Redshift
- Business needs evolve constantly — yesterday they wanted raw events, today they want rollups, tomorrow they want cohort analysis
And guess what that means? Yup — more transformations.
4. It's a marketing trick
Zero ETL sounds like "zero effort", and who wouldn't want that? Vendors love the term because it sells.
- Snowflake talks about querying external data "on the fly"
- Databricks promotes Delta Sharing as the end of pipelines
- API-first platforms promise data that's "ready to use"
But under the hood, it's just old ideas with new branding. The ETL hasn't gone away — it's just been relabeled.
Zero ETL doesn't eliminate your job. It just moves the complexity to new layers — APIs, integrations, real-time streams. You'll still be cleaning data, writing logic, and debugging failures. Call it ETL, ZeroETL, or HyperRealTime DataFlow-as-a-Service — the dirty work is still yours.
Modern Data Stack
I'm fucking tired of the term "Modern Data Stack".
Сan we finally admit that Modern Data Stack™ is just a phrase vendors use to sell the same 6 tools to every company?
It started with good intentions — a way to describe the shift to cloud-native, modular tools like Snowflake, dbt, and Airflow that changed how we build pipelines and analytics workflows. And for a while, it meant something.
But now?
It's just meaningless marketing noise.
- Selling an ETL tool? "It's part of the Modern Data Stack!"
- Pushing a dashboard tool with zero integration features? "Modern Data Stack!"
- LLM that writes SQL and forgets context? "Modern Data Stack!"
- Platform that's basically Excel with a SQL wrapper? You guessed it.
Just calling something "modern" doesn't make it better. In fact, for a lot of smaller teams and early-stage startups, it's massive overkill. Do you really need Snowflake + dbt + Looker to analyze 10GB of data? Probably not.
The problem is the phrase has lost all meaning. It's just a shiny label slapped on tools to make them look cutting-edge, whether they're useful or not. It creates a false sense of simplicity. People pitch it like it's a plug-and-play solution for every data problem — it's not. There's no one-size-fits-all stack. It ignores the messiness of real-world data work. Connecting systems, cleaning data, handling schema drift, managing cost — that's the hard part. Tools can help, but they don't do the job for you.
We need to stop glorifying tools and start focusing on fundamentals.
Ask yourself:
- Can you design scalable, maintainable pipelines?
- Do you actually understand the business you're supporting?
- Can you model your company's data clearly and accurately?
- Are you optimizing for cost and performance, or just stacking tools for the sake of it?
These are the questions that matter - not whether you're using the "Modern Data Stack" or the "Hipster Data Stack" or "Gen Z Data Stack" or whatever comes next.
How to Stay Sane
Let's wrap this up with some practical advice, because I understand — the buzzwords and marketing aren't going anywhere. That being said, you can still choose how much power they hold over your work. Here are a few tips to cut through the noise:
1. Translate marketing speak into engineering reality
When someone says "Data Fabric" ask: "Which systems are we integrating? Where does the metadata live? Who's maintaining it?"
2. Always anchor discussions in real business questions
If they say "we need actionable insights" ask: "What decision are you trying to make? What would you do differently if you had that insight?"
3. Be tool-skeptical, not tool-hostile
New tools are fine. Hype isn't. Choose what solves your problem with the least overhead, not what has the best branding.
4. Focus on fundamentals
So instead of chasing shiny trends, focus on the fundamentals:
- Build scalable, reliable pipelines
- Manage data quality
- Monitor your systems
- Document your models
- Optimize for performance and scale
- Understand your business
Final Thoughts
Look, I'm not saying all innovation is bad. Some of the stuff wrapped in buzzwords is genuinely useful, but only if you understand what it actually is and how to use it intentionally. Just don't confuse shiny terms with actual engineering.
Tools don't solve problems. People do. No buzzword can replace craftsmanship.
Mic drop